
Dans le cadre de l’expérimentation conduite avec le soutien du ministère de la Culture, le TMNlab a organisé le 2 décembre un atelier dédié à la structuration des données du spectacle vivant.
Cet atelier, en visioconférence, a réuni des profils d’horizons variés pendant près de trois heures. Après une présentation de la démarche et des résultats de travaux déjà menés ou initiés, les participants se sont répartis en sous-groupes de travail autour de quatre cas d’usage identifiés en phase exploratoire. Les échanges ont montré une convergence des intérêts autour de la nécessité de trouver un modèle parent interopérable.
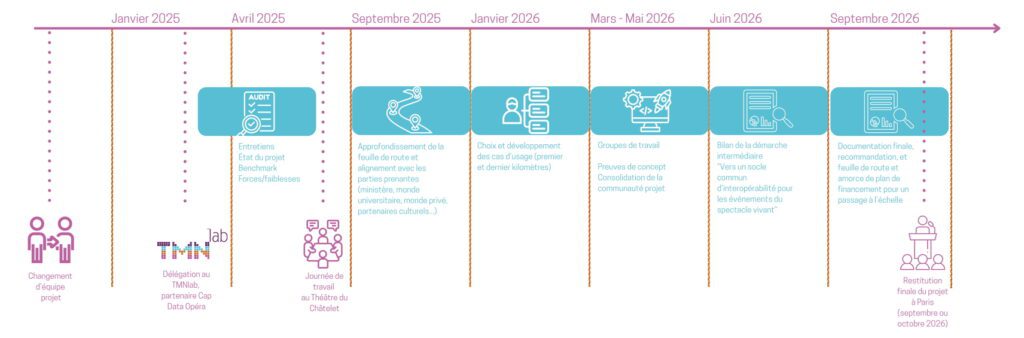
L’expérimentation, qui se poursuivra jusqu’à l’été, doit permettre de préfigurer les bases pour des évolutions visant l’amélioration de la circulation des données du spectacle vivant et une plus grande visibilité des spectacles et représentations. Combinant approches théoriques et pratiques, cette phase s’appuiera sur des preuves de concept (en anglais proofs of concept – POC) pour tester la faisabilité des pistes étudiées et faire ressortir les conditions de réussite d’un déploiement plus étendu.
Synthèse de l’atelier
Introduction – Présentation de la démarche
Par Sophie Zeller – Cheffe du service du spectacle vivant, adjointe du directeur général de la création artistique (DGCA) au ministère de la Culture
Le ministère de la Culture, avec la DGCA et le soutien essentiel du service du numérique, mène depuis plusieurs années un chantier majeur sur la donnée. Le projet d’interopérabilité des données du spectacle vivant s’inscrit pleinement dans cette dynamique et rejoint les travaux du TMNlab, partenaire principal du ministère sur ce sujet.
L’objectif d’un référentiel commun est double. D’une part, améliorer la découvrabilité des informations en ligne : à l’ère des moteurs de recherche, puis aujourd’hui de l’IA générative, la structuration et la qualité des données sont devenues indispensables pour que les spectacles et programmations soient correctement moissonnés, retrouvés et recommandés. D’autre part, répondre aux besoins internes des structures et du ministère : billetterie, plannings, outils de pilotage et démarches déclaratives reposent tous sur des échanges de données, dont l’interopérabilité est essentielle pour simplifier le travail, fiabiliser les informations et alléger les charges pour les déclarants comme pour l’administration.
Une première ébauche de référentiel, fondée sur le langage Schema.org, a été amorcée par la DGCA et le service du numérique. Mais ce standard ne sera réellement utile que s’il est aligné avec les pratiques du terrain et adapté aux réalités des acteurs. C’est pourquoi une démarche de co-construction a été engagée, co-portée par le TMNlab, afin de travailler collectivement, à partir de cas d’usage concrets, les aspects techniques et pratiques du futur standard.
Ce premier atelier inaugure ainsi la démarche, qui ne pourra être fructueuse qu’avec les contributions de toutes les structures réunies aujourd’hui.
Support de la présentation
Participants de l’atelier
Près de 70 personnes représentant différents métiers et structures :
Entrepreneurs du spectacle vivant
- Festival d’Avignon
- L’Azimut – Pôle cirque
- Numéridanse
- Opéra Comique
- Opéra de Lyon
- Réseau 535
- Réunion des Opéras de France
- Théâtre du Châtelet
Institutionnels
- ARTCENA
- ASTP
- CNM
- Ministère de la Culture
- ONDA
- Office de tourisme ONLYLYON Tourisme
- Pass Culture
- SACD
- SACEM
- TMNlab
Expert·es indépendant·es
R&D
- Laboratoire LATICCE
- Avignon Université
Opérateurs économiques
- Apidae
- BCubix
- Cervocom
- FESTIK
- HEEDS
- ideactiv
- IT4Culture
- Logilab
- Mapado
- Movinmotion
- OpenAgenda
- Orfeo
- Ressources SI
- Rezo Zero
- Rodrigue
- Supersonicks
- Tix
Restitution des 4 sous-groupes thématiques
01 – Circulation des données internes de programmation dans les systèmes d’information (SI) des entrepreneurs de spectacles vivants (ESV)
Objectif : Améliorer la circulation des données entre les logiciels de gestion de l’activité artistique (planification, production), la billetterie, le site internet, etc.
Points de friction : Saisies manuelles multiples sur les différents outils au risque de nuire à la qualité de vie au travail (augmentation de la charge, perte de temps et de sens), risque de dégrader la qualité des données.
Position du groupe : Les SI ont besoin d’avoir des logiciels qui puissent communiquer facilement entre eux, pour que les données soient intégrées sans avoir à les retravailler, les recopier, etc.
Pistes évoquées :
- Se concentrer en priorité sur l’interopérabilité de ces paramètres : lieu, jauge, type d’événement, type de public
- Travailler sur un identifiant unique par événement
- Définir un méta-modèle et une taxonomie partagée
- Favoriser une approche data-centric (basant la conception sur la structuration des données)
Cas d’usage à développer : Saisie initiale des données de programmation sur une plateforme puis report automatique dans d’autres outils du SI.
02 – Circulation des données hors des systèmes d’information (SI) des entrepreneurs de spectacles vivants (ESV)
Objectif : Améliorer les échanges de données entre les outils internes des SI des ESV et les structures externes qui ont besoin de récupérer ces données (organismes collecteurs pour la gestion des droits, agrégateurs de contenus, agendas culturels, etc.).
Points de friction : Saisies manuelles multiples auprès d’opérateurs distincts demandant les données dans des formats ou selon des référentiels différents.
Position du groupe : Démontrer l’interopérabilité des données en permettant à certains acteurs de produire des données dans un format d’échange commun, tandis que d’autres intègrent et utilisent ces données dans leur propre système d’information.
Pistes évoquées :
- Utiliser schema.org et intégrer différents référentiels métier pour structurer les données du spectacle vivant selon un cadre commun
- Questionner l’investissement (temporel, financier, cognitif) d’une harmonisation pour les différents acteurs par rapport aux gains dans l’usage quotidien
- Centraliser les données sur une base commune de spectacles
- Publier davantage de données sur data.gouv
- Définir une politique d’identifiants uniques (spectacle, représentation)
- Étudier un outil automatique de collecte
Cas d’usage à développer : Production des données de programmation d’un ESV dans un format automatiquement exploitable, sans ressaisie manuelle, et commun à plusieurs consommateurs (organismes collecteurs, agrégateurs, etc.).
03 – Découvrabilité territoriale de l’offre culturelle
Objectif : Tester l’intégration et l’exposition des données de programmation dans les bases de données touristiques depuis les sites internet des structures.
Points de friction : Saisies manuelles multiples dans des systèmes avec des référentiels différents (voir absents), carence de la programmation culturelle dans les bases de tourisme.
Position du groupe : Nécessité de mieux partager les données de spectacles entre le site internet d’un lieu et celui de l’office du tourisme pour mieux les valoriser sans multiplier les saisies manuelles. Région lyonnaise comme territoire d’expérimentation.
Pistes évoquées :
- Créer un standard d’alignement des référentiels
- Mettre en place un flux automatisé et réplicable entre les producteurs (opéras, théâtres, etc.) et les consommateurs (offices de tourisme, APIDAE, etc.)
- Identifier clairement le parcours de la donnée en intégrant les cas de création, modification, suppression
- Voir s’il est possible de s’appuyer sur des plateformes et agrégateurs existants
Cas d’usage à développer : Test de la remontée de données intégrées sur le site de l’Opéra de Lyon (et d’autres ESV du territoire lyonnais) vers Apidae pour diffusion sur le site de l’office du tourisme de Lyon.
04 – Découvrabilité sur le web (moteurs de recherche et IA)
Objectif : Créer un registre de référence pour la découvrabilité des évènements du spectacle dans les moteurs de recherche et d’IA afin de garantir une indexation optimale.
Points de friction : Faible découvrabilité des offres de spectacle vivant dans les moteurs de recherche (SEO*) et moteurs de réponses / LLM (GEO**).
* SEO (Search Engine Optimization) soit optimisation pour les moteurs de recherche (c’est le référencement naturel qui vise à améliorer la position d’un contenu dans les résutats d’un moteur de recherche).
** GEO (Generative Engine Optimization) soit optimisation pour les moteurs génératifs (vise à améliorer la visibilité d’informations dans les réponses générées par IA).
Position du groupe : Intérêt de pouvoir tester la mise en place d’un registre de référence des spectacles à destination des moteurs de recherche (Google, Qwant, Bing…) et de réponse (IA).
Pistes évoquées :
- Prendre contact directement avec des moteurs de recherche et de réponse par IA pour identifier les stratégies les plus efficaces à mettre en place pour améliorer la découvrabilité des données
- Préparer un jeu de données de test suffisamment complet (circonscrit à quelques centaines de lieux de diffusion) pour l’expérimentation d’un registre
- Partager des statistiques d’audience et de positionnement des sites pour pouvoir mesurer l’impact sur la découvrabilité des mesures testées et voir comment mener des tests sur les moteurs de réponse par IA
Cas d’usage à développer : Saisie initiale des données de programmation sur le CMS d’un site de lieu puis transmission automatique vers un registre de référence suivant les recommandations d’un moteur de recherche et de réponse par IA afin d’analyser l’impact sur la visibilité des sites de lieux après quelques mois.
Prochaines étapes
Développer les cas d’usage identifiés dans chaque groupe de travail thématique pour aboutir à des projets de preuve de concept pertinents.
Préparer et mener des ateliers de travail, avec des représentants des parties prenantes concernées et des professionnels métier, pour la réalisation et la documentation de ces preuves de concept en équipes agiles et resserrées.
Initier une réflexion transversale en vue d’un référentiel commun de données.
Envie de participer ?
Vous êtes intéressé·e par une ou plusieurs des thématiques traitées ou vous souhaitez prendre part à cette expérimentation ?
Écrivez à Roxane Tchernia par email roxane.tchernia(at)tmnlab.com ou via la messagerie du site.
En fonction des besoins sur le projet, de votre profil et de vos possibilités, vous pourrez être invité·e à rejoindre un groupe de travail, renforcer une expertise, apporter un regard constructif…