
Aujourd’hui, les spectacles ont souvent une vie numérique brève ou invisible. Les artistes sont présents, mais leurs œuvres, leurs dates, leurs trajectoires ne le sont pas. Le projet Cap Data tente de réparer cette invisibilité numérique structurelle. Mais structurer des données, ce n’est pas juste une affaire de code, c’est une affaire de culture. Voici pourquoi nous avons mené cet audit.
Sommaire de la publication :
- Contexte et méthode
- A quoi sert un tel projet ?
- Pourquoi le TMNlab soutient Cap data ?
- Quel diagnostic posons-nous sur le projet aujourd’hui ?
- Une feuille de route collective
- Remerciements
- Ressources supplémentaires
Disclaimer : ce compte-rendu évolue, nourri des retours des participants et de la veille permanente sur le sujet. Partagez de préférence le lien que le PDF de la page.
Contexte et méthode
Au printemps 2025, le TMNlab a conduit, en partenariat avec la Réunion des Opéras de France, un audit approfondi du projet Cap Data Opéra. Ce projet visait à structurer et mutualiser les données du spectacle vivant dans une logique d’infrastructure commune.
Pour évaluer son déploiement et sa capacité à produire les effets attendus, nous avons mené une série d’entretiens avec les acteurs impliqués et analysé en parallèle la documentation technique, les choix d’architecture et les usages émergents. Cette enquête a été conduite par Anne Le Gall (déléguée générale du TMNlab) et Stelio Tzonis (membre du conseil d’administration), en combinant approche qualitative, veille stratégique et expertise sectorielle.
Point d’orgue de cette démarche : une journée de travail organisée le 20 juin 2025 au Théâtre du Châtelet, réunissant une trentaine de participants aux profils complémentaires — chercheur·euses, professionnel·les du spectacle vivant, spécialistes de la donnée culturelle, agences web, expert·es en web sémantique, juristes — pour mettre en débat les enseignements de l’audit et dessiner les orientations futures du projet.
A quoi sert un tel projet ?
« J’écris depuis un moment sur la façon dont la visibilité numérique est mal comprise — surtout dans les secteurs des arts, de la culture et du public. On investit dans des campagnes, des stratégies de contenu, mais on ignore l’élément dont tout dépend : la structure. La découvrabilité est un acte d’agentivité. Les métadonnées sont une infrastructure. Mais rien de tout cela ne compte si les gens ne peuvent pas s’en servir concrètement. »
Tammy Lee, CEO, Culture Creates | Semantic Technology for the Arts – Québec
Améliorer la découvrabilité [définition] des œuvres
Les algorithmes ne voient pas ce qu’ils ne comprennent pas.
- Aujourd’hui, une grande part des contenus du spectacle vivant est invisible sur les moteurs de recherche, les assistants vocaux, les outils d’IA gen ou les plateformes culturelles, faute de données structurées.
- Une infrastructure partagée permet d’exposer les spectacles dans des formats lisibles par les machines (schema.org, RDF), donc visibles et activables.
- Une telle infrastructure permet l’archivage de la production contemporaine.
Créer une base commune pour des usages multiples
Une donnée bien structurée peut être utilisée de façon multiple, sans être ressaisie.
- Export vers les agendas, les plateformes de billetterie, les observatoires publics.
- Automatisation de tâches (fiches artistes, archivage, statistiques, formulaires déclaratifs).
- Croisement avec les données d’audience, de territoire, ou les référentiels culturels.
- Perspectives de recherche, en particulier sur les politiques culturelles ou l’histoire quantitative
Alléger la charge de travail dans les lieux culturels
Trop de saisies, trop d’outils, pas assez de sens.
- Une donnée unique, réutilisable et alignée avec les référentiels communs permet de limiter les doubles saisies et les erreurs.
- On réduit la dépendance à des prestataires, on améliore la continuité documentaire.
Fédérer un écosystème autour de communs numériques
Chaque lieu produit des données, mais isolément elles ont peu de valeur.
- En reliant les données (spectacles, lieux, artistes, œuvres), on crée un graphe de connaissances qui bénéficie à tous.
- Cela ouvre des coopérations entre lieux, disciplines, réseaux et développeurs, en France comme à l’international.
Préparer l’avenir (IA, API publiques, politiques publiques)
Ce qui n’est pas structuré ne sera ni analysé, ni transmis, ni soutenu.
- Pour que le spectacle vivant existe demain dans les systèmes d’IA générative, les plateformes, les politiques culturelles orientées « données », il faut que ses informations soient lisibles, interopérables, accessibles.
- Une telle infrastructure rend possible des services innovants (chatbot, recommandation, tourisme culturel, mesure d’impact) tout en garantissant un pilotage éthique et souverain.
EN BREF : Ce que Cap Data permettrait demain dans un lieu culturel
Être automatiquement référencé sur Google et dans les IA vocales
Publier une fiche spectacle complète sans saisie multiple
Créer un parcours de visite augmenté autour d’un opéra ou d’une pièce de théâtre
Contribuer à un observatoire national sans ressaisir ses données
Identifier automatiquement des artistes programmés dans plusieurs lieux
UNE DÉFINITION : QU’EST-CE QUE LA DÉCOUVRABILITÉ ?
La découvrabilité d’un contenu ou d’une offre culturelle dans l’environnement numérique (web, plateformes, moteurs IAgen…) se réfère à sa disponibilité en ligne et à sa capacité à être repéré parmi un vaste ensemble d’autres contenus, en particulier par une personne qui n’en faisait pas précisément la recherche.
Une stratégie de découvrabilité repose sur la maîtrise d’un dialogue avec les humains, via une stratégie de marketing et médiation digital, et avec la machine, via une stratégie de référencement à court terme, une infrastructure de métadonnées liées à moyen et long terme.
[Cliquez ici pour accéder aux ressources Découvrabilité du TMNlab]
Pourquoi le TMNlab soutient Cap Data ?
Les données culturelles ne sont pas un luxe technique.
Elles sont un levier stratégique pour renforcer la visibilité, la découvrabilité et l’impact du spectacle vivant. Le projet Cap Data, initié par Eudes Peyre à la Réunion des Opéras de France avec le soutien par France 2030 – Expérience augmentée du spectacle vivant, est une initiative partenariale unique en son genre pour structurer les données du spectacle vivant avec une logique d’infrastructure partagée, d’intérêt général.
Ce n’est pas un projet technique, c’est un projet de souveraineté culturelle et de service public.
Pour se déployer, un tel projet doit reposer sur la mobilisation d’une communauté : pour décrire, former, documenter, mutualiser, accompagner les lieux culturels dans cette transformation. Pour les encapaciter et faire des institutions culturelles les pilotes d’un tel projet. C’est pourquoi le TMNlab en est partenaire depuis le début.
Nous portons un plaidoyer pour une infrastructure publique de la donnée culturelle, pilotée par les acteurs eux-mêmes, interopérable avec d’autres initiatives (archives, billetterie, observatoires…). L’innovation naît quand la donnée est un commun, disponible, documenté et réutilisable. Et cette innovation doit servir celles et ceux qui font la culture.
Le projet doit permettre :
- Structuration fine de la donnée : une ontologie métier spécifique au spectacle vivant, compatible avec les standards du web (Schema.org) et du web sémantique [définition] (RDF [définition], modèles sémantiques de référence, référentiels pivots comme DBPedia, Wikidata…)
- Interopérabilité native : des connecteurs pour Drupal/WordPress, un SDK [définition] PHP, une API et un entrepôt SPARQL [définition] pour exposer des données exploitables par des moteurs de recherche, agrégateurs, startups, collectivités, médias
- Nouveaux usages possibles : services contextuels (chatbots, parcours culturels augmentés), enrichissement d’outils CRM, outils de recommandation, valorisation touristique ou territoriale, préservation d’un patrimoine, évaluation et recherches
Notre approche se veut connectée aux enjeux contemporains : découvrabilité, transparence, IA, écologie des systèmes d’information. Et centrée sur celles et ceux qui font. Les données seules ne font pas infrastructure : il faut une communauté pour valider, construire et utiliser.
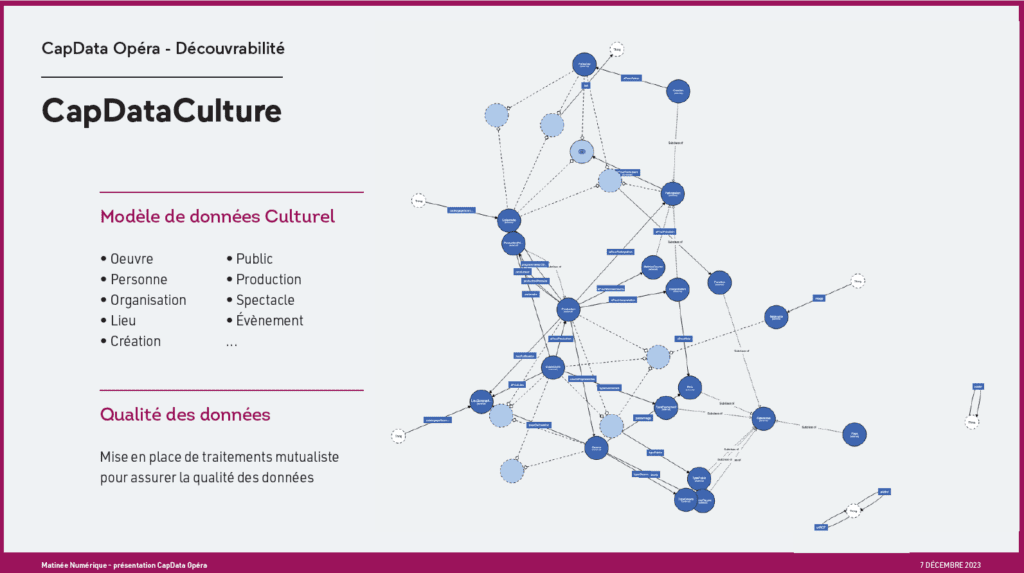
DES DÉFINITIONS : QU’EST-CE QUE LE WEB SÉMANTIQUE ?
Le web sémantique est une évolution du web – conceptualisée dans les années 60 et formalisée dans les années 2000 – qui permet aux ordinateurs de comprendre le sens des données qu’ils lisent. Contrairement au web classique, qui est fait pour les humains (avec du texte, des images, etc.), le web sémantique organise les informations de façon à ce que les machines puissent les relier, les comparer et en tirer du sens automatiquement.
En pratique, cela permet par exemple :
– de relier automatiquement un spectacle à son metteur en scène, à la salle où il est joué, à une base de données comme Wikidata ou à une fiche d’artiste ;
– de faciliter les recherches croisées et les recommandations intelligentes ;
– de garantir que les informations circulent entre les outils et les plateformes, sans doublons ni erreurs.
Un projet en web sémantique repose sur des référentiels (ontologie, vocabulaire contrôlé) et des standards (RDF, SPARQL). Nous vous proposons quelques définitions pour accompagner votre lecture.
Ontologie
Une ontologie est une sorte de dictionnaire structuré qui définit les concepts d’un domaine (ex : « spectacle », « artiste », « lieu », « date ») et la manière dont ils sont reliés entre eux (ex : « un spectacle est joué dans un lieu », « un artiste crée un spectacle »). C’est une grammaire partagée pour décrire le monde du spectacle.
Elle sert à parler le même langage entre machines et humains, même si les bases de données viennent de lieux ou de logiciels différents.
RDF (Resource Description Framework)
Le RDF est un langage standard qui permet d’écrire les informations de manière claire pour les ordinateurs, sous forme de triplets : sujet – prédicat – objet. Exemple : « Roméo et Juliette – a pour auteur – William Shakespeare » ou « Festival d’Avignon – a lieu à – Avignon« .
C’est la brique de base du web sémantique : chaque triplet décrit une petite relation, et des milliers de triplets permettent de construire une base de connaissances riche et interconnectée.
SPARQL
SPARQL est un langage de requête, comme une version web sémantique de « Google » : il permet d’interroger une base de données RDF pour retrouver des informations précises. Par exemple : Montre-moi tous les spectacles créés par des femmes entre 2000 et 2020. Quels spectacles ont été joués à Paris par une compagnie belge ?
C’est l’équivalent sémantique du SQL (gestion de bases de données), mais adapté aux données en triplets.
SDK (Software Development Kit)
Un SDK, ou « kit de développement logiciel », est une boîte à outils numérique mise à disposition des développeurs pour interagir facilement avec une base de données ou un service numérique.
Dans le web sémantique, un SDK peut par exemple permettre de : générer ou lire des données en RDF, se connecter à une base SPARQL, intégrer les données dans une application web ou mobile.
C’est un accélérateur technique pour les développeurs.
Quel diagnostic posons-nous sur le projet aujourd’hui ?
L’initiative portée par la ROF est unique en France et indispensable à une politique publique numérique forte. Le travail mené grâce au financement France 2030 a permis d’amorcer un travail structurant et de rassembler des acteurs indispensables. Cap Data ouvre un avenir pour une infrastructure de données ambitieuse.
- Solidité technique : une base RDF, un SDK open source, un plugin fonctionnel (Drupal, WordPress) et un alignement partiel avec schema.org ont été mis en place. Les technologies sont solides, existent depuis longtemps. Acteurs français privés (Logilab) et de la recherche (Université Rennes 2, projet ERC From Stage to Data) sont pointus et mobilisés.
- Vision structurante : l’approche par ontologie permet une granularité forte adaptée au spectacle vivant, au-delà des standards généralistes comme schema.org. Tout en assurant un alignement avec ce standard indispensable à la découvrabilité des offres et encore trop peu déployé.
- Écosystème mobilisé : des partenaires techniques (Logilab, Bluedrop, Rézo Zéro), des lieux pionniers (Théâtre du Châtelet, Opéra National de Bordeaux, Théâtre National de l’Opéra Comique, Opéra de Lyon), des acteurs publics (Ministère, DGCA), des chercheurs et développeurs impliqués, des acteurs intermédiaires (ROF, Artcena, Les Archives du Spectacle), des acteurs internationaux (SCAPIN en Belgique, ArsData et Footlight CMS au Canada). La communauté naissante est déjà engagée.
Le projet financé dans le cadre de l’AAP France 2030 a atteint ses objectifs : il a créé une preuve de concept avec une ontologie, un graphe de connaissance et des connecteurs opérationnels. L’enjeu n’est pas technique, il porte sur les usages.
Le projet est donc entré dans sa dernière phase : le développement d’une communauté et la réflexion sur son passage à l’échelle.
L’audit réalisé par le TMNlab pour dessiner la future feuille de route a fait émerger les points suivants :
1. Entrée technique unique trop exigeante pour les lieux
- Implémentation via CMS (Drupal, WordPress) sur des sites existants pertinente mais jugée trop complexe pour être une solution universelle.
- Dépendance à des développeurs peu familiers avec RDF/SPARQL.
- Coût d’entrée dissuasif pour les petites et très petites structures (ticket à 2 000 € et 5 à 10 jours de travail cumulé, parfois égal au coût total de leur site).
PRIORITÉS
- Proposer des entrées diversifiées :
- via des connecteurs légers (plugin déjà existant pour Drupal et WordPress)
- via un cadre de référence pour les refontes de sites internet,
- via un scrapping pour les structures ne pouvant pas encore adapter leur site Internet,
- via une saisie intermédiaire en dernier recours ou s’il n’y a pas de site internet.
- Mutualiser le paramétrage initial (ex. aide à la modélisation, mappage CMS).
- Créer des “kits de démarrage” ou des dispositifs d’accompagnement métier.
2. Absence de cas d’usage immédiat lisible et difficulté à comprendre le projet
- L’infrastructure est perçue comme “intéressante” mais la question de l’impact concret à court terme sur le quotidien des professionnels du spectacle vivant revient souvent.
- Les bénéfices concrets ne sont pas visibles à court terme pour les contributeurs
- Le projet est perçu comme « très technique » et peu accessible par les professionnels
PRIORITÉS
- Travailler l’identité du projet, son nom, son plaidoyer.
- Adopter une logique de “produit minimum viable” (PMV). Prioriser 2–3 cas d’usage transformateurs, simples et partagés (ex : référencement amélioré sur Google ou une IAgen, travail sur un territoire défini, exposition de la programmation sur Deezer, Pass Culture…).
- Diffuser des démonstrations de ce que “ça permet” : export live, moteur de recherche enrichi, publication automatisée, cartographies…
- Appuyer le discours du projet sur les politiques publiques (découvrabilité, IA, data, culture).
3. Manque de portage collectif et de gouvernance claire
- Le départ du chef de projet numérique de la ROF comme celui d’une référente projet pour l’un des opéras associés ont temporairement fragilisé le projet.
- La ROF seule ne peut maintenir le projet, la volonté d’élargissement au-delà de l’opéra est actée.
- Le projet dans sa version « prototype » n’avait pas encore fédéré une communauté ni intégré de vision contradictoire.
PRIORITÉS
- Formaliser un consortium inter-réseaux avec un mandat et une feuille de route partagée.
- Former des groupes de travail visibles et identifiables, agiles, hétérogènes et représentatifs.
- Documenter de façon ouverte et avec différents niveaux d’accès (grand public, technique).
- Construire « en faisant », depuis le terrain et avec les acteurs publics, la future gouvernance du projet.
- Poser les bases d’un modèle économique coopératif (maintenance, support, développement).
4. Difficulté à embarquer les développeurs et équipes SI
- RDF et SPARQL sont jugés “intéressants mais intimidants”.
- Faible culture commune entre métiers artistiques, communication et développeurs.
PRIORITÉS
- Créer un espace développeurs (docs, tutos, échanges, rencontres).
- Organiser des “bootcamps RDF pour devs culturels”.
- Développer des API (REST, GraphQL…) pour simplifier l’intégration.
5. Modèle d’ontologie trop spécifique, difficile à aligner
- L’ontologie Cap Data est très fine et sectorielle (centrée sur l’opéra), mais difficile à maintenir, s’approprier et animer faute d’une communauté l’ayant produite.
- La place des standards tel que schema.org/Event (standard de référence pour les données structurées sur Internet, sur les pages Web, dans les messages électroniques), LIDO-MC ou Cidoc-CRM doit être interrogée.
- L’accès aux données sans API et principalement en SPARQL crée un risque d’isolement de la donnée ou d’impossibilité de réutilisation externe.
PRIORITÉS
- Créer un groupe dédié pour décider du référentiel à retenir.
- Poursuivre l’alignement du projet avec Schema.org/Event (et Wikidata) tout en conservant l’approche sémantique plus riche.
- Reprendre l’état de l’art réalisé par Rennes 2 pour le projet From Stage to Data et leurs travaux sur Linked Art basé sur Cidoc-CRM, ainsi que les travaux et recommandations du Ministère de la Culture (Politique des données – profil d’application LIDO-MC). Documenter ces choix.
- S’inscrire dans les travaux internationaux, européens et nationaux sur la question.
6. Fragilité et exhaustivité des données contributives
- Qualité, cohérence, mise à jour : la donnée reste fragile si laissée à l’unique responsabilité des lieux.
- Risque d’effet “garbage in, garbage out” si les données sont partielles ou fausses.
- Seuil de contribution à atteindre pour débloquer des usages.
PRIORITÉS
- Structurer une stratégie de qualité / validation (identifiants, sources, révisions croisées), avec des rôles clairs. Construire une gouvernance des données.
- S’appuyer sur l’expertise d’acteurs existants, construire et/ou renforcer les partenariats : BNF, Artcena, Les Archives du Spectacle, les centres de ressources des institutions (CND, Philharmonie…) et réseaux (ROF, ASN, ACDN…), les projets témoins à l’étranger (Canada, Belgique).
- Cibler des structures au regard d’un cas d’usage défini (territoire défini, type de label…).
7. Trop faible distinction entre infrastructure et interface
- Confusion fréquente entre “site web” et “infrastructure”.
- Réflexes “portail d’agenda” encore très présents dans les attentes.
PRIORITÉS
- Pédagogie continue : “les applications passent, les données restent”.
- Valoriser les flux, pas les vitrines.
- Présenter un benchmark pour renforcer le choix stratégique du projet.
Une feuille de route collective
Le travail de la journée du 20 juin et une série d’entretien qui ont suivi ont permis de formuler une feuille de route pour la suite du projet avec trois axes transversaux :
Se focaliser sur les deux problèmes prioritaires
- Premier kilomètre : l’accès aux données des lieux sur un jeu de données délimité au regard d’un cas d’usage identifié
- Dernier kilomètre : démontrer un premier cas d’usage à valeur ajoutée pour le secteur / les structures impliquées
Co-construire avec des lieux pilotes variés
- Créer un groupe de bêta-testeurs représentatif (disciplines, tailles, modèles économiques).
- Intégrer dès le départ développeurs, DSI, responsables communication ou documentation.
- Documenter les retours d’expérience en temps réel.
Fonder une communauté métier durable
- Créer un espace de coopération continu (rencontres, chat, wiki, docs partagées).
- Former des ambassadeurs dans les réseaux et les lieux.
- Organiser des temps d’échange entre pairs : “Café Cap Data”, forums tech/data/culture…
Objectif à court et moyen termes
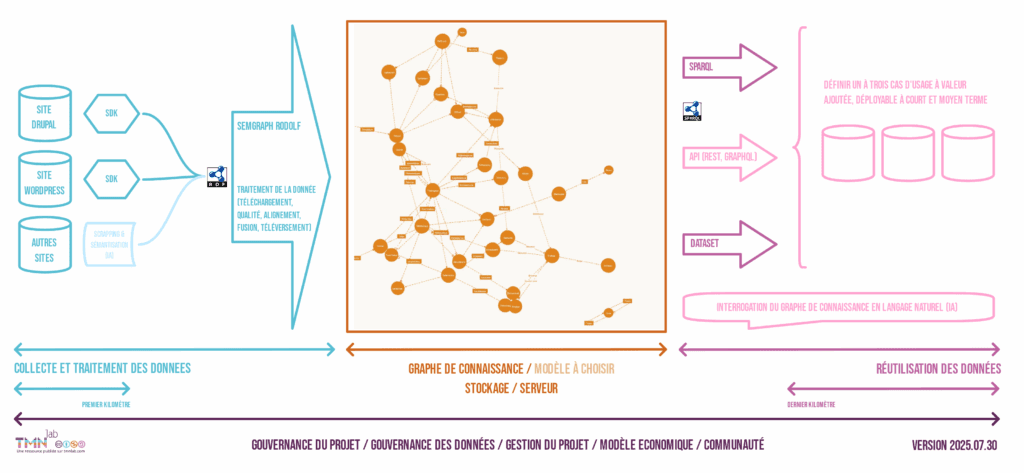
| Chantiers | Objectif court-terme (sept 2025 – janv 2026) | Objectif moyen-terme (déc 2025 – oct 2026) |
| Premier kilomètre : Collecte de données | valider le principe d’un mode de collecte (conception, test, correction, validation) permettant un passage à l’échelle | produire un jeu de données complet pour un cas d’usage (ex : toutes les données « spectacle vivant » d’un territoire, toutes les données d’un type de label…) |
| Dernier kilomètre : Cas d’usage | définir un à trois cas d’usage avec des partenaires | démontrer la création de valeur de l’infrastructure au regard d’un usage concret, en évaluant le degré de sémantisation nécessaire |
| Ontologie et standards | étudier les standards et modèles de données existants, évaluer le coût d’une bascule de Cap Data vers un nouveau modèle | modifier le modèle du projet et rejoindre une communauté autour d’une ontologie plus appropriable et standardisée, alignée avec les parties prenantes clés |
| Modèle économique | définir le plan de financement des différents chantiers « preuves de concept » | définir le modèle économique garantissant la pérennité du projet, son intérêt général et sa pertinence pour stimuler l’innovation |
| Identité et plaidoyer | repositionner l’identité du projet (nom, valeurs, objectifs, cibles) | décliner un plan d’action vis-à-vis de trois cibles clés (institutions productrices de données, tiers financeurs publics et privés, tiers réutilisateurs) et activer une stratégie de plaidoyer |
Schématisation du projet actuel (ontologie Cap Data Opéra) et de ses projections d’usages « idéales »
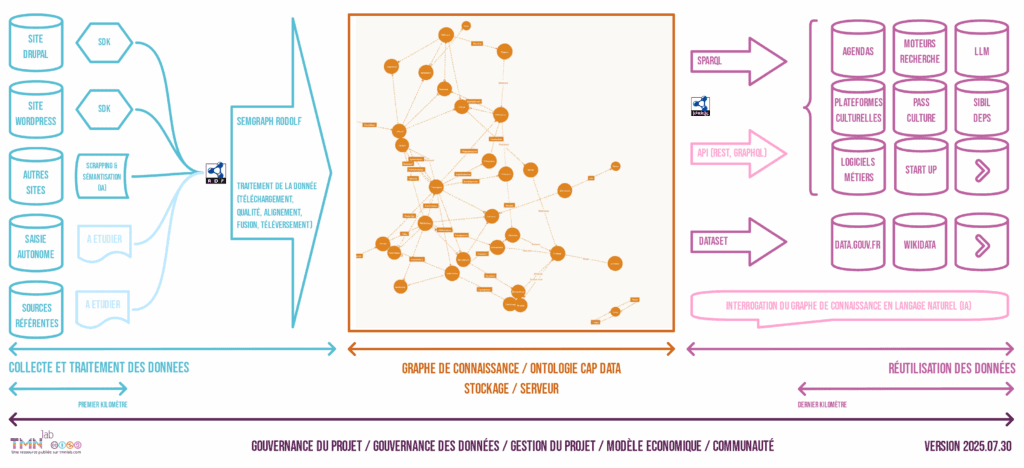
EN BREF : Qui fait quoi ?
exemple :
Professionnel d’un lieu : je publie sur mon site une fiche spectacle dans un format structuré
Développeur : je branche le plugin sur le CMS
Chercheur / documentaliste : je contribue à l’ontologie
Réseau professionnel : je relaie les usages, les freins, les besoins
Financeur : je soutiens une infrastructure durable et souveraine
Réutilisateur : j’exploite les données et je contribue au commun (temps, financement)
Envie de rejoindre un chantier, de contribuer ponctuellement ou de partager une initiative proche ? Écrivez à Anne Le Gall par email anne.legall@tmnlab.com ou via la messagerie du site @annelegall
Remerciements
A l’équipe de cette phase d’audit :
- Frédéric Pérouchine, directeur de la Réunion des Opéras de France
- Anne Le Gall, cofondatrice et délégué générale du TMNlab
- Stelio Tzonis, membres du conseil d’administration du TMNlab
Aux participants et participantes à la journée du 20 juin 2025 :
- Structures culturelles : Auxane Dutronc et Hélène Guilbert (Opéra de Lyon), Juliette Tissot-Vidal (Opéra Comique), Alice Poncet (Numéridanse), Thomas Amouroux (Théâtre du Châtelet), Hadrien Jeanne (Odéon, Théâtre de l’Europe), Abdel Yassir-Montet (Centre National de la Danse), Frédéric Désaphi (Philharmonie de Paris), Stéphane Hardel (Les Amandiers)
- Associations professionnelles : Brice Gessler (Artcena), David Roux (ASTP), Luc Wanlin (Scapin, Belgique), Sylvain Brunerie (Les Archives du Spectacle), Guilhem Rouille (Onda)
- Recherche : Clarisse Bardiot (Université Rennes 2, projet ERC From Stage to Data), Emilie Pamart et Maud Pelissier Thieriot (Université d’Avignon)
- Éditeurs logiciel et développement : Nicolas Chauvat et Alexandre Richardson (Logilab), Romain Lange (Open Agenda), Thomas Chenevier (Ideactiv), Ambroise Maupate et Jean-Baptiste Marchand (Rezo Zero), Sophia Moussaid (Festik), Arnaud Levy (Noesya – Université Bordeaux Montaigne)
- Juristes : Fayrouze Masmi-Dazi et Umberto Valenza (Dazi Avocat)
Aux personnes interrogées ou ayant nourris la réflexion au printemps 2025 :
- Dimitri Kesteloot et Yann Rotil (Bluedrop)
- Tammy Lee (Culture Creates, Canada)
- Jihen Landolsi (Ministère de la Culture)
- Marie-Véronique Leroy (Ministère de la Culture)
- Anne-Laure Janeczek (Ministère de la Culture)
- Conseil d’administration de la Réunion des Opéras de France
Et à Eudes Peyre, qui a initié et piloté le projet Cap Data Opéra en tant que chargé de mission ressources et développement numérique à la Réunion des Opéras de France dès 2021, s’est investi auprès de la Communauté TMNlab en tant que membre de son CA jusqu’à la fin 2024, et continue à oeuvrer pour le spectacle vivant en tant que Chargé de mission Circulation et ouverture des données au Ministère de la Culture.
Ressources supplémentaires
Plus d’informations sur le projet Cap Data Opéra / Réunion des Opéras de France
- CapData Opéra – France 2030 sur le site de la ROF
- Documentation sur GitLab
- Article CapData Opéra : faciliter l’interopérabilité des données des maisons d’opéra
- Conférence SWIB24 « CapData Opéra: ease data interoperability for opera houses » par Nicolas Chauvat
- Et un Café TMNlab sur le projet exceptionnellement ouvert sans restriction, par Eudes Peyre

Le travail d’audit et l’organisation de cette journée s’inscrivent dans le projet soutenu par l’État dans le cadre du dispositif « Expérience augmentée du spectacle vivant » de France 2030 opéré par la Caisse des Dépôts et sont réalisés en partenariat avec la Réunion des Opéras de France.
Ressources issues d’autres projets : FROM STAGE TO DATA à Rennes
- Les projets SCAPIN en Belgique et STAGE à l’Université Rennes 2, de la mémoire à la découvrabilité ?
- Projet ERC From Stage to Data – Université Rennes 2
- From Stage to Data : Ontologies for Performing Arts and Linked Open Data (2024)
- Arts de la scène et humanités numériques. Des traces aux données (2021)
Ressources issues d’autres projets : SCAPIN en Belgique
- Les projets SCAPIN en Belgique et STAGE à l’Université Rennes 2, de la mémoire à la découvrabilité ?
- SCAPIN Un projet collaboratif de mémoire numérique des arts de la scène en FWB
Ressources issues d’autres projets : ARTSDATA au Canada / Québec
- Une voie prometteuse pour promouvoir la gouvernance des données dans le secteur des arts de la scène : analyser les chartes et les principes pour la gouvernance des données (2021)
- ArtsData, graphe de connaissances pancanadien pour les arts
- Culture Creates, semantic technology for the arts
- Arrimage / Mapping avec l’ontologie ArtsData
- Rapport annuel ArtsData
- Projet de loi sur la découvrabilité au Québec
Ressources issues d’autres projets : autres travaux